表示并学习复杂关系
神经网络模型有什么特点?深度学习是什么?如何「学习」?
在让机器学会经验中,我们已经了解了「机器学习」的基本概念,了解了「学习」的过程和方法。本节我们主要继续介绍「模型」的概念;在前文的最后,我们使用一个一元回归模型的例子说明了网络结构的重要性。
为了构建更有表达能力的模型,神经网络(Neural Network),应运而生。
神经网络的「语言」
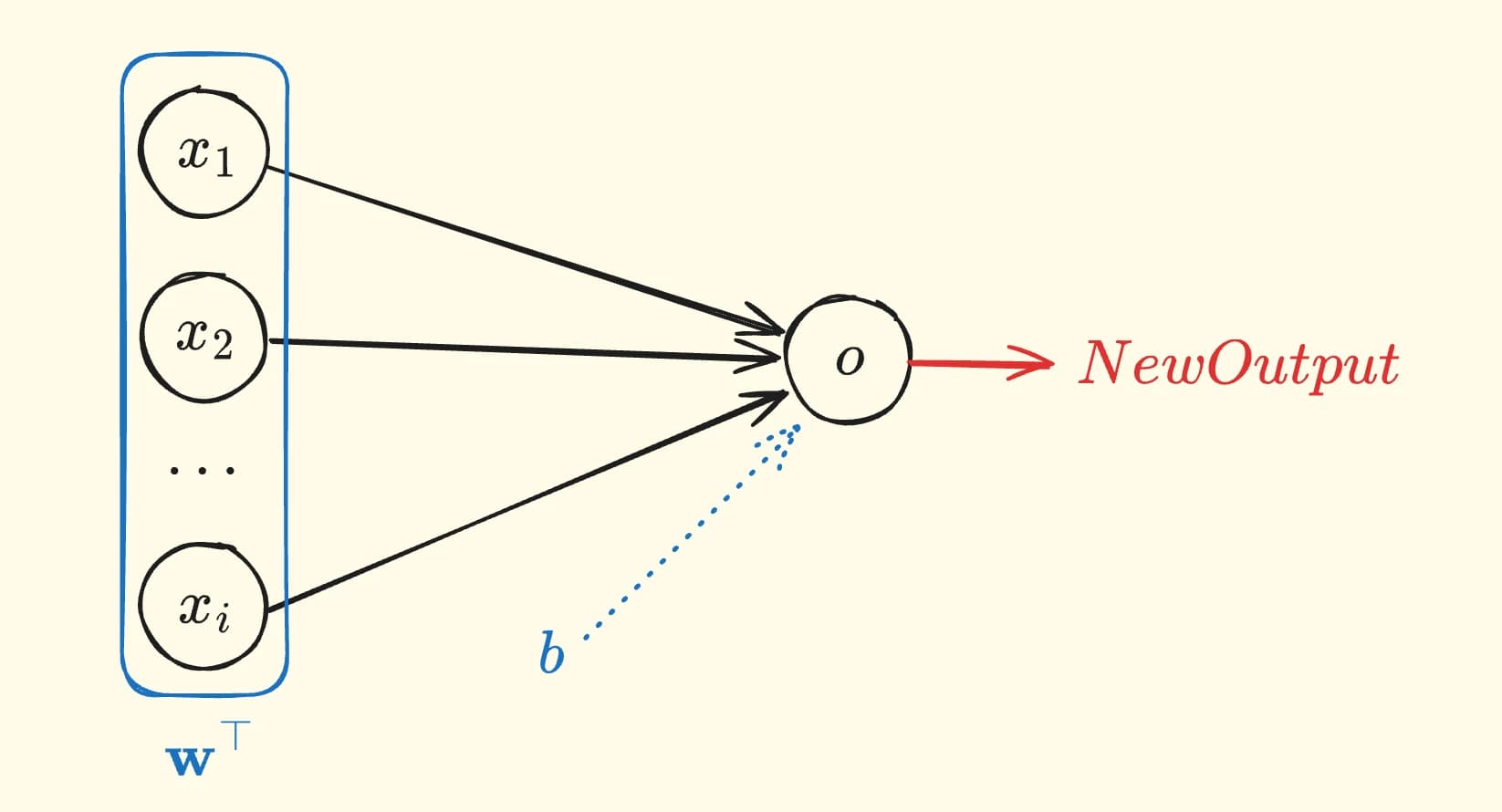
神经元
线性函数并不是一无是处的,它在数学上是优雅的,同时具备单调、可微等性质,其体现的思想具有复用的空间。受到生物神经元的启发,生物学上一个神经元似乎会接收来自多个其他神经元的输出,并产生一个新的输出,我们可以使用线形模型建模这个过程:
其中, 表示了 个前驱神经元的输入值(标量), 表示了当前神经元受到前一个神经元影响的程度,称为权重(Weight)。这里的 用于整体偏移这个神经元输出的数值的大小(和数学上的截距类似),称为偏置(Bias)。该神经元可以表示平面内的全部线形关系。
简写
我们也可以将它们写成向量乘法形式:
从中可以看出,一个神经元的输入是一个向量,即 1 维张量,输出是一个标量。
单个神经元就已经构成了一个最小的线形神经网络,其数学本质和前文提到的一元线性回归完全一致。它作为一个完善的计算单元(最小的网络),可以处理来自我们多个数据输入(甚至多个前驱神经元的输出),并再产生一个输出。
堆叠
当我们把多个神经元组织在一起时,就形成了真正的神经网络。
选择
在构建神经网络时,我们面临更宽还是更深的选择。更宽是指在同一层放置更多神经元,让模型能同时捕捉更多平行特征;更深则是堆叠更多层,让每层都对前一层的输出进行再次组合。
实验和理论都表明,更深具有明显更多的优势:每增加一层,模型就能把简单模式组合成更高层次的抽象特征,用更少的总参数表达更复杂的函数,这在图像等数据上效率远超单纯增加宽度。
在神经网络中,层与层之间是按顺序连接的。具体来说,第 层的所有神经元的输出会用于构成第 层的输入向量。
第 层的每个神经元,其输入都来自第 层神经元的输出。
如果第 层的每一个神经元都与第 层的每一个神经元相连,这种连接方式被称为「全连接」。此时,第 层每个神经元的输入向量长度,等于第 层神经元的个数。
注意
并不是所有情况都采用全连接,在某些网络中,我们会使用不完全连接(或称稀疏连接),例如后续即将介绍的卷积神经网络(CNN),它只让神经元与输入的局部区域相连,从而显著减少参数量并提高效率。
深度神经网络
当神经网络的层数不断增加时,我们就称它为深度神经网络(Deep Neural Network)。
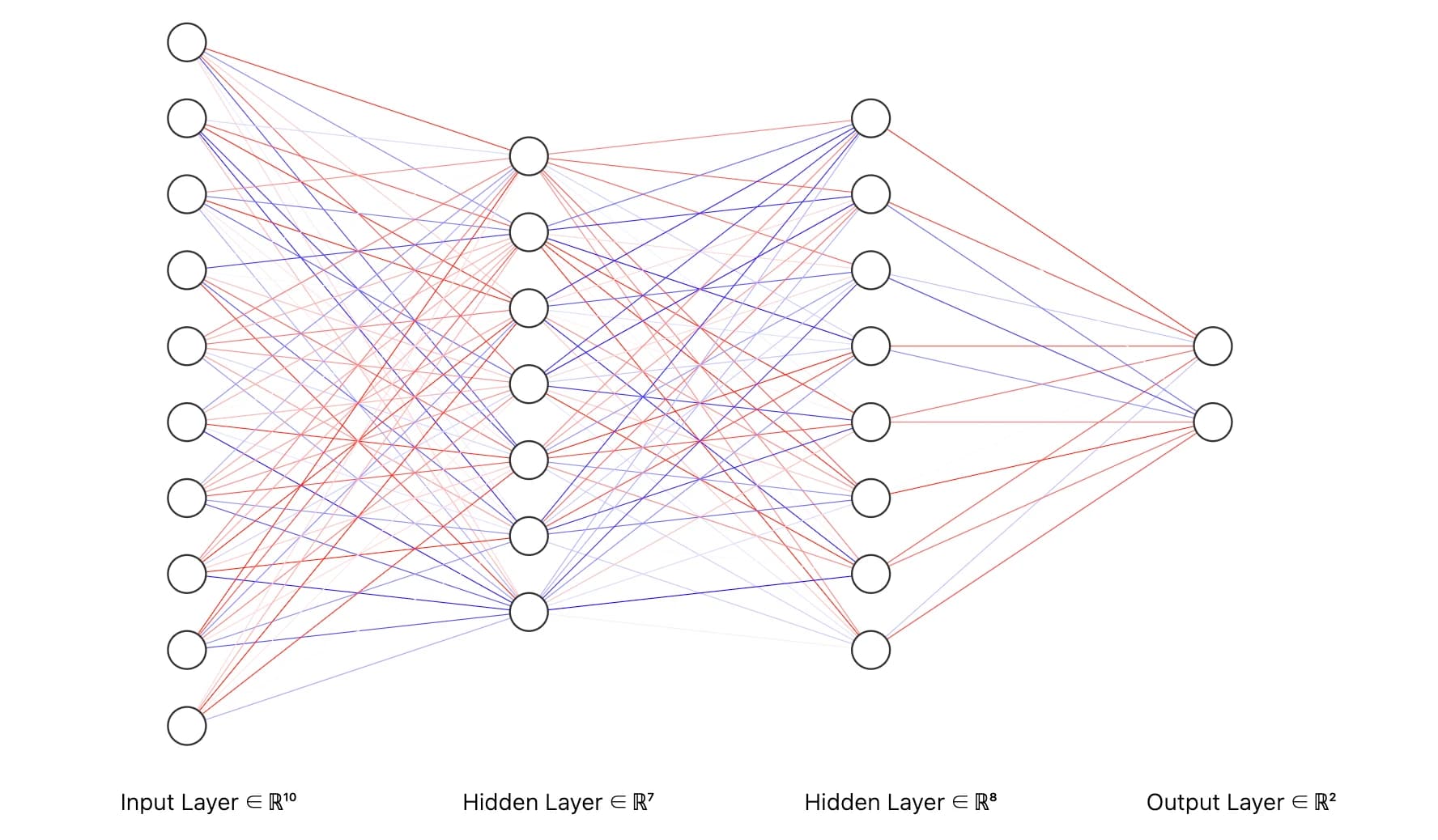
深度的具体含义是指隐藏层(Hidden Layer)的数量(输入层和输出层不算在内的层数)。深度越大,模型就能在更多层之间进行逐层抽象和特征组合。
印象 · 深度学习
深度学习(Deep Learning)正是利用深度神经网络进行机器学习的技术。它让模型从数据中自动提炼多层次的经验,突破了传统模型的表达能力上限。在我们将要进行的图像修复实验中,正是深度神经网络(如 CNN)让模型具备把模糊图片变清晰高阶经验。
多层感知机
我们前面讨论的深度神经网络,其最经典、最基础的形式就是多层感知机(Multi-Layer Perceptron,简称 MLP)。
MLP 正是通过多层全连接的方式,将线性神经元层层堆叠,实现层次化的特征学习。
然而,如果你仔细思考就会发现:如果所有层都是纯线性的,无论堆叠多少层,最终都可以数学化简为单层线性模型。
因此,我们必须让神经网络具备非线性的表达能力,才能真正拟合更复杂的函数关系。
要做到这一点,我们需要在每一层线性变换之后,对其输出结果进行一次非线性变换。这种非线性变换不再是简单的加权求和,而是通过一个固定的非线性函数(例如让直线“弯曲”成曲线的函数),对线性结果进行非线性映射,从而打破线性复合的限制。
这种专门用于引入非线性的函数,我们称之为激活函数(Activation Function)。激活函数对线性变换的结果进行非线性映射,使得整个网络能够拟合高度复杂的函数关系。
加入激活函数后,网络的复合关系就无法再简单化简为单层线性。以一个两层网络为例:
假设第一层:
则有第二层:
其中 为激活函数, 被称为活性值(Activation Value)。由于 是非线性函数,无法像线性层那样直接代入合并,因此两层叠加无法等价于任何单层线性形式。
注意 · 激活函数的本质
激活函数并不是单独的一层,它没有可学习参数,只是一个固定的非线性变换过程,插在线性变换之后,作为中间计算步骤存在。
再谈「优化器」
我们已经构建了多层感知机,它通过线性变换 + 激活函数获得了非线性的表达能力。但现在出现了一个实际问题:模型里有成千上万个可学习的参数(权重和偏置),我们需要一种系统的方法来调整这些参数,让损失的值不断降低。
如何系统地调整参数
要调整参数,我们必须先知道每个参数对最终损失的影响大小,然后决定每个参数应该往哪个方向移动、移动多少。
链式法则的作用
我们先回顾一个高中学过的数学工具——链式法则。它的核心思想是:在多次复合的函数映射中,最终输出对初始输入的变化率,等于每一步映射的变化率依次相乘。
计算图与自动微分
为了让链式法则在实际网络中高效运行,我们把整个前向计算过程组织成一个计算图。
概念 · 前向计算
从输入层开始,依次经过每一层线性变换和激活函数,最终得到预测值和损失的完整计算流程。
计算图是一个有向无环图(DAG)。它的无环特性保证了我们可以先完成前向计算(从输入到输出),然后从输出到输入反向传递梯度(反向传播)。
借助计算图 + 链式法则,计算机可以自动完成所有偏导数的计算,这就是自动微分(Automatic Differentiation)技术。
梯度与梯度下降
通过自动微分,我们得到每个参数相对于损失的偏导数。当模型有多个参数时,所有这些偏导数合在一起就构成了一个向量,这个向量被称为梯度(Gradient)——它完整描述了每个参数对损失的影响程度。
梯度告诉我们参数应该往哪个方向调整才能让损失下降。具体的调整方法叫做梯度下降(Gradient Descent):
其中 代表所有可学习参数, 是学习率(Learning Rate),用于控制每次调整的步长。 就是梯度。
整个训练过程分为两步:
- 前向传播:完成前向计算,得到预测值和损失。
- 反向传播:从损失开始,沿着计算图反向逐层计算梯度,并更新所有参数。
随机梯度下降
如果每次梯度下降都使用全部数据来计算梯度,计算量会非常大。
为了解决这个问题,人们提出了随机梯度下降(Stochastic Gradient Descent,SGD)。SGD 每次只随机选取一小批数据(mini-batch)来计算梯度并更新参数。这样既能大幅降低计算成本,又能让模型更快收敛,同时还能帮助模型避免陷入局部最优。
印象 · 优化器的统一框架
优化器(Optimizer)就是把自动微分 + 梯度下降(或其变种如 SGD)封装起来的完整机制。它让多层感知机这样复杂的深度模型能够真正被训练。
再谈「推理」
在前面的内容中,我们已经多次提到「推理」(Inference)这个概念。
推理是指模型在训练完成之后,使用已经学习好的参数对新数据进行预测的过程。它本质上就是只进行前向传播,让数据从输入层依次经过每一层的线性变换和激活函数,最终得到模型的输出结果。
与训练过程不同,推理时我们不需要计算损失,也不需要进行反向传播和参数更新。因此,推理的计算量更小,速度更快,也更加节省资源。
那么,推理时模型使用的参数是从哪里来的呢?
在模型训练结束后,我们会把所有学到的可学习参数(包括权重和偏置)保存下来。这种保存下来的文件通常被称为检查点(Checkpoint)。检查点记录了模型在训练过程中的某个特定时刻的状态。
进行推理时,我们首先需要加载这个检查点中的参数到模型结构中,让模型恢复到训练完成后的状态,然后才能对新的输入数据进行预测。
注意
加载权重是一种常见的简化说法,但其实并不完全严谨。因为检查点中保存的不仅仅是权重(Weight),还包括每一层的偏置(Bias)。更准确的说法是加载模型参数或加载检查点。
本文作者